Loading...Loading...Loading...
On-Premise AI
The difference between renting and owning your intelligence.
AI that runs on your hardware, trained on your data,
owned by your organization. Nothing leaves your network.
100% Private
Enterprise Ready
0 bytessent to third parties
Built With Our Proprietary Software
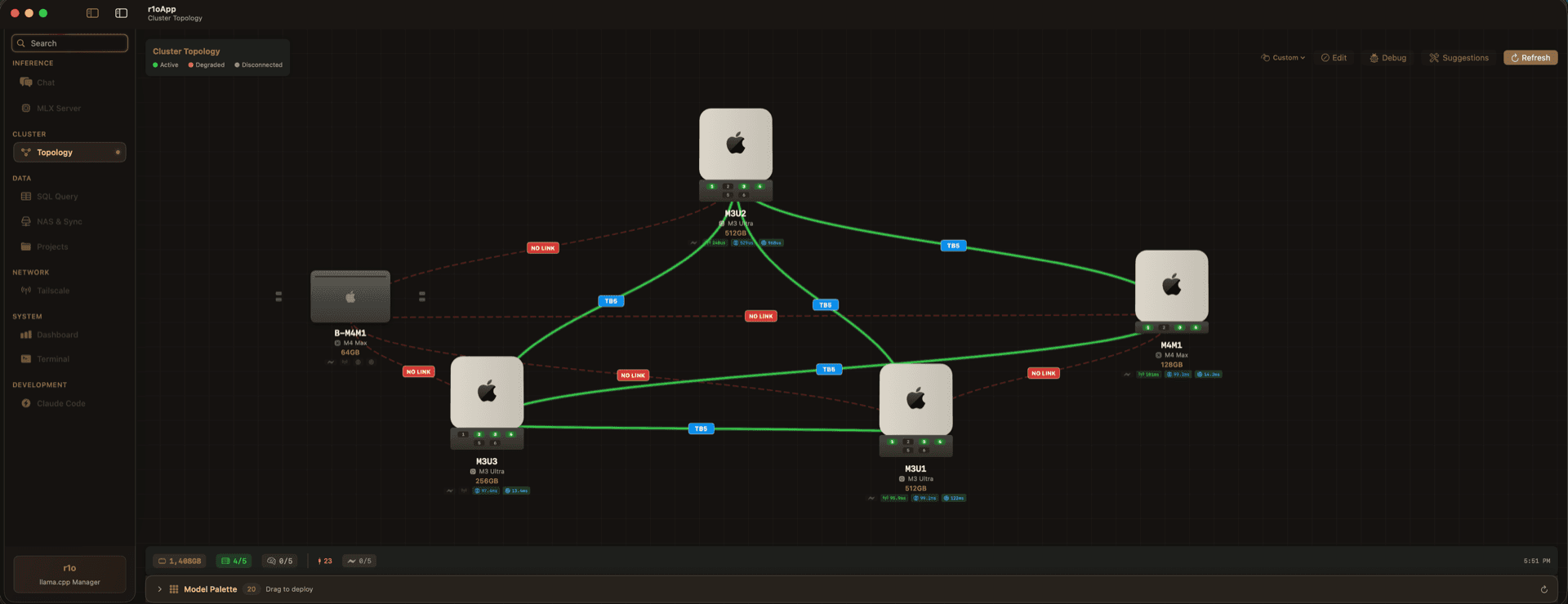
Your AI
command center
Powered by our proprietary cluster orchestration platform. Monitor models, track inference, and manage your entire AI infrastructure from a single pane of glass.
Real-time cluster topology
See every node, connection, and model across your fleet
Distributed inference
Automatically route queries across available hardware
Zero-config networking
RDMA mesh auto-discovers and connects all nodes
f
fib0.ai/Cluster TopologyLive
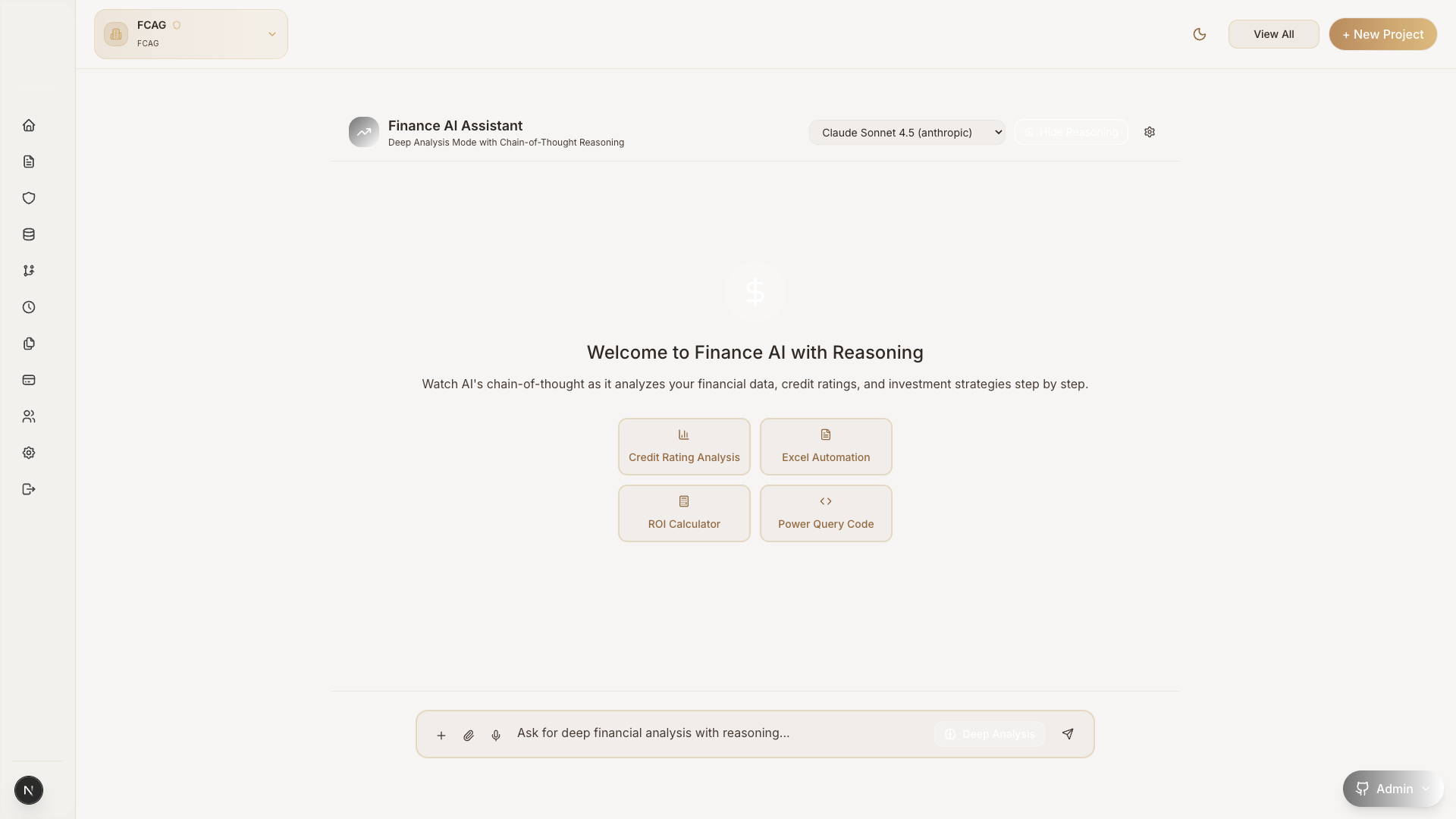
Conversational AI Interface
AI that knows
your business
A private AI assistant trained on your data. Ask questions about costs, contracts, documents, and operations — get instant, accurate answers without exposing a single byte to the cloud.
Context-aware responses
Understands your org structure, projects, and terminology
Tool-augmented reasoning
Queries databases, analyzes costs, and generates reports live
Complete audit trail
Every interaction logged locally for compliance
White-Labeled For You
Your own custom,
private AI model.
Every deployment is branded to your organization. Your logo, your domain, your data — an AI platform your team will recognize as their own.
✦Your Logo
🔗Your Domain
🔒Your Data Only
⚡Custom Fine-Tuned
Why fib0
Stop renting your intelligence.
Every prompt to a cloud API teaches someone else's model your business. fib0 runs on hardware you own — your intelligence stays yours.
Your Context Is Your Moat
Every prompt you send to a cloud API teaches their model your patterns. Your strategy, your clients, your competitive edge — leaking one query at a time. Own the model, keep the moat.
Compliance Requires It
HIPAA, SOC 2, GDPR — regulators don’t care about your AI vendor’s privacy page. Local infrastructure means you own the audit trail, the data residency, and the answer.
Zero Marginal Cost
No per-token billing. No rate limits. No surprise invoices. Once the hardware is yours, every query after that is free — run it a thousand times a day.
Ready to get started?
The future of AI is local.
Join forward-thinking companies using local AI to protect their data, control costs, and maintain competitive advantage.